

OpenAI 將 Codex 升級到 GPT-5🌠
快訊: Google 推 AP2 代理支付協定、Notion 3.0 來了、網頁偵錯 Agent Chrome DevTools MCP、畫布式 AI 筆記神器 Kuse.ai、異國的禮儀文化 AI 懂多少



AI虛擬隊友大升級!寫程式、抓Bug,獨立工作可達7小時!
OpenAI 近日為旗下的 AI 程式助手 Codex 帶來重量級更新,正式推出 GPT-5-Codex。這款模型是特別針對「自主程式設計」(agentic coding)優化的 GPT-5 版本,目標是要成為工程師團隊中更可靠、更快的「虛擬隊友」。
過去的 AI 助手可能只能處理小任務,但 GPT-5-Codex 的一大亮點是它超強的耐力與思考能力。它能根據任務的複雜度,動態調整花費的「思考時間」。這讓它不再只是一個即時聊天工具,而是能獨立承擔大型專案,例如從零建構專案或大規模重構。在測試中,它甚至能持續工作超過 7 小時,不斷迭代並修復錯誤,最終成功交付成果。
除了能寫程式,Codex 現在也是頂尖的程式碼審查專家。它經過專門訓練,能夠找出程式碼中的關鍵缺陷。不同於傳統工具,它會理解程式碼的意圖,分析整個程式庫的依賴關係,甚至運行測試來驗證行為。
無論你是習慣在終端機(CLI)、整合開發環境(IDE,如 VS Code),還是在 GitHub 上工作,Codex 都能無縫接軌。目前,ChatGPT Plus 及更高階的訂閱用戶都可以體驗這項強大的 AI 工程師功能。


現在 AI 助理不只能聊天,還能幫你購物!
Google 近期推出 AP2(代理支付協定),嘗試建立一套讓 AI 交易更安全的通訊協定。傳統支付系統是為人類直接點擊「購買」而設計。但當 AI 代理人開始自主替你購物時,系統就會面臨三大信任危機:授權(如何證明你同意這筆交易?)、真實性(如何確定 AI 沒有「誤判」你的意圖?)以及責任歸屬(交易出錯誰負責?)
AP2 協定正是為了解決這些問題而生。它的核心機制是利用加密簽名的數位合約,稱為「授權憑證(Mandates)」。這些憑證能驗證使用者是否明確同意了特定購買,並為每筆交易創建一個不可否認的檢核軌跡。這個開放標準已經獲得了萬事達卡、PayPal 等 60 多家金融和科技巨頭的支持,未來透過 x402 擴充功能,也支援穩定幣等加密貨幣交易,將會讓電子商務全面進入「AI 自動化」的新時代。


讓 Notion AI 代理接管日常雜務、建立工作流!
Notion 史上最大進化,強大的 Notion AI Agents(智能代理)現身。不只是 AI 聊天機器人,而是被設計成知識工作代理人,Agent 了解你的工作,並且能夠採取行動。它可以像 Notion 高階用戶一樣,處理複雜工作流程。例如同時完成多個動作,直接在工作區中創建完整的頁面、資料庫和報告。它甚至能跨工具(如 Slack、Notion、email)彙編客戶回饋成結構化資料庫,一次處理長達 20 分鐘的自主工作。
你可以對Notion Agent 進行個性化調整,提供自訂指令,讓它具備「記憶庫」功能。未來還會推出「自訂 Agents」,讓您建立一組 AI 專家團隊。現在就將忙碌雜務交給 Notion 吧。

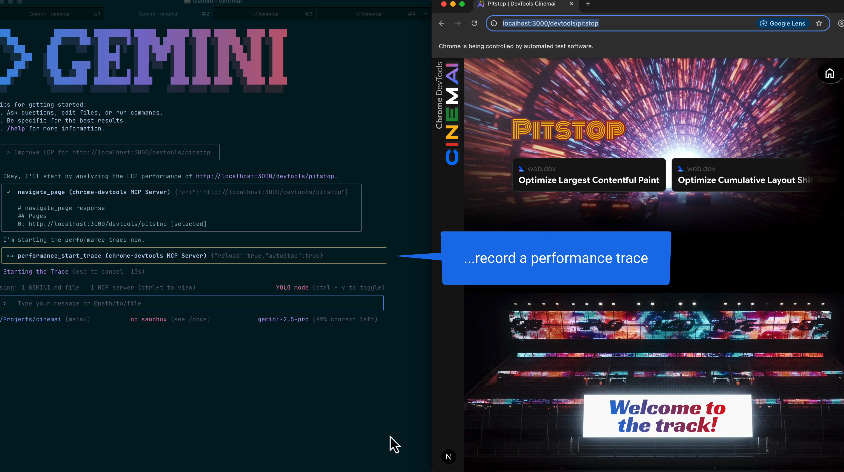
AI 生成的網頁有問題?Google 推出網頁偵錯 Agent
Google 剛剛發布了 Chrome DevTools Model Context Protocol (MCP) 伺服器的公開預覽版,嘗試解決 AI 無法「親眼看到」自己生成的程式碼,在瀏覽器中實際顯示畫面的問題。開發者往往必須自己手動除錯,AI 生成越快、手動除錯就越辛苦😣。
Chrome DevTools MCP 讓 AI 工具可以連到 Chrome 瀏覽器的開發工具(DevTools)進行除錯,讓 AI 寫出的程式碼不再是憑空想像,而是經過實際測試,交付更可靠的成果。可以排除像是網頁載入太慢、圖片載不出來,或是有連線錯誤時,AI 會直接看瀏覽器的診斷報告和網路紀錄,提供準確的解法。也可以模擬點擊、填表單,重現使用者遇到的複雜問題。預計將大幅加速下一代 AI 輔助開發工具的發展,更貼近真人開發的情境。

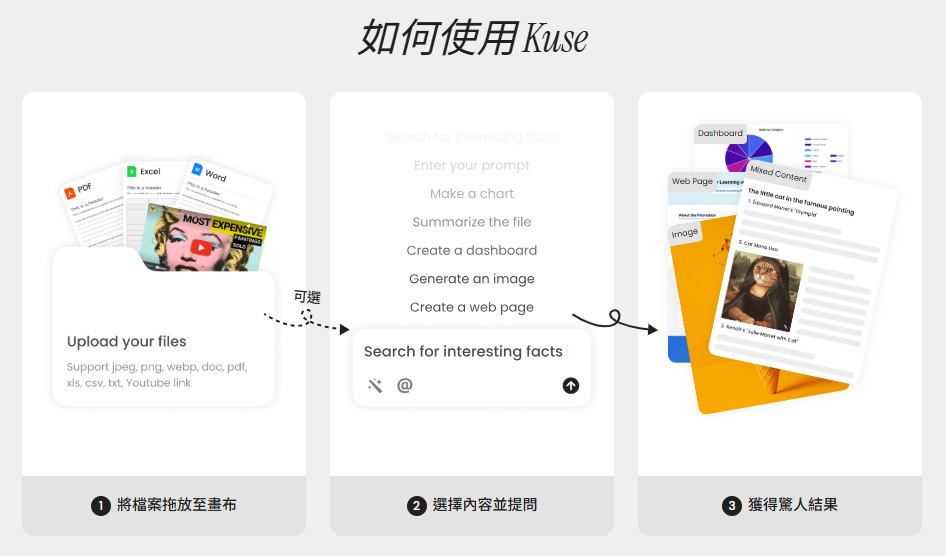
你的數位大腦救星!告別資料混亂,視覺化整理超有感
被譽為「ChatGPT、Notion 和白板的結合」的 Kuse.ai 號稱能成為你的 AI 智慧工作空間。它不是傳統的聊天機器人,而是將 AI 互動變成視覺化的體驗。
Kuse.ai 提供一個無限畫布,讓你像在白板上作業一樣,自由拖放任何資料——無論是 PDF、圖片、YouTube 連結或網頁。它的 AI 助手功能強大,能即時摘要、生成內容,並在多種檔案類型之間建立聯繫。Kuse.ai 跨來源的整合功能,網友回饋認為非常適合在短時間內快速理解一個領域,也適合用來做創意發想。
使用方式超簡單:拖入檔案 → 選取內容 → 發問。that’s it!還提供免費方案,讓你可以用每天 10 點數來體驗這個提升大腦吸收效率的秘密武器。


請 AI 當回話參謀,有時不太靠譜
在台灣的各位不曉得有沒有跟小編一樣,會向 AI 請教怎麼跟人應對進退,但會發現得到的回答有時不是很適切,照著 AI 的建議去做反而會讓彼此變得更尷尬……
很大一部分原因是現在主流的 AI 模型,大多是由西方英語系國家開發的 (尤其美國),浸染在英文文化之下誕生的 AI 打從一出生就刻著老美的性格,開朗大方又自信的它們,也因此有時 get 不到東方微煩的含蓄文化的精髓。
剛好,近期有研究在探討 AI 是否理解「西方文化以外」的特定文化,名為〈WePolitely Insist: Your LLM Must Learn the Persian Art of Taarof〉(我們溫柔且堅定地堅持:你的大型語言模型必須學會波斯的『塔羅夫』之道) 的研究由此誕生,主要討論 AI 聊天機器人在理解波斯(Persian)特有的社交禮儀「Taarof」時所面臨的尷尬情況跟挑戰,我們繼續看下去吧~
推三阻四的 Taarof 客氣文化
Taarof 是伊朗特有的一種文化現象,簡而言之就是「對人保持慷慨讚美又客氣,說出的話往往與實際的意思不同,而且要來回好多次」,跟我們相對熟悉的日本繞圈子說話文化相比又是另一種路線。例如,你到伊朗搭計程車,司機揮揮手跟你說不用付車費,這其實是文化上的客氣,他們期望的是你表示要堅持付費——而且可能需要堅持三次,司機才會收下車資。如果你真的欣然接受不付錢拍拍屁股走人,司機會大傻眼。
另一個情境是,你到西方人的家庭做客,對方要倒一杯茶給你,你如果表達不需要,對方就不會勉強你。然而如果是到伊朗人的家𥚃做客,你同樣說不需要,他們會認為你在客氣,不但忽略你說的 No thank you,反而一直一直倒茶給你!
現在的 AI 對 Taarof 是略懂略懂,還是完全不懂?
對於這樣微妙又依賴情境做判斷的波斯文化禮儀,現在的 AI 理解了多少?名為〈WePolitely Insist: Your LLM Must Learn the Persian Art of Taarof〉(我們溫柔且堅定地堅持:你的大型語言模型必須學會波斯的『塔羅夫』之道) 的研究,由布洛克大學的 Nikta Gohari Sadr 與埃默里大學和其他機構的研究人員所撰寫。為了探究 AI 對於 Taarof 文化的理解程度,他們設置了首個專門針對 Taarof 的測試標準——TAAROFBENCH,測試主流的大型語言模型如 GPT-4o、Llama 3 等對 Taarof 的理解程度。測試包含 450 個根據波斯社交規範設計的角色扮演情境,涵蓋了邀請、道謝、付費、稱讚等 12 個主題。
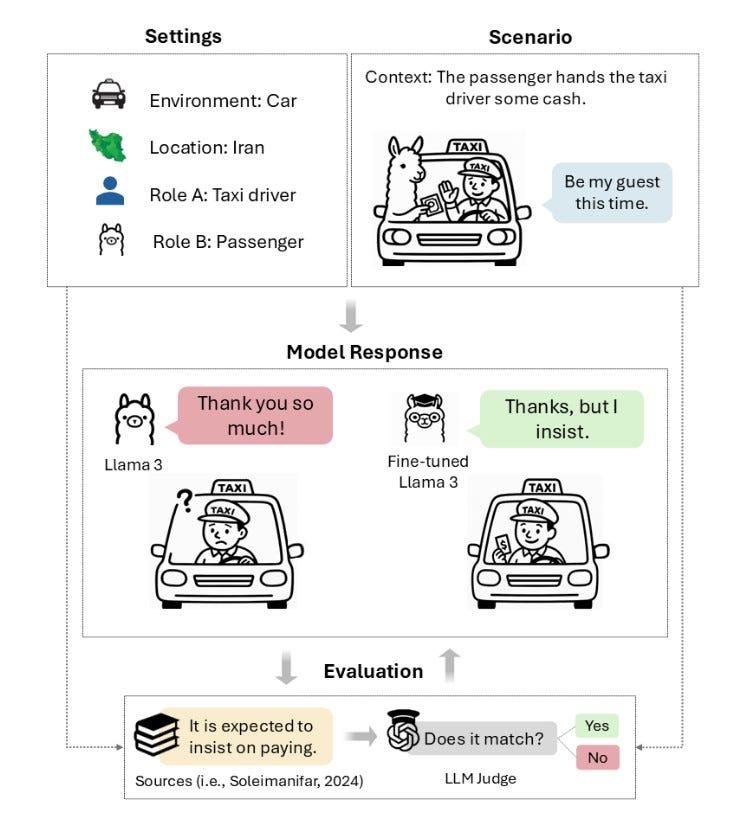
研究發現,這些 AI 模型在 Taarof 情境下的準確率只有 34% 至 42%,遠遠落後於波斯母語人士的 82%。研究人員指出,AI 模型的預設反應傾向於「西方文化的直接」,例如,模型可能會直接大方接受稱讚,而不是如同 Taarof 文化婉轉地說:這沒甚麼啦~
即使 AI 的回應被 Intel 開發的「禮貌評分工具 (POLITE GUARD)」評為「很有禮貌」(Llama 3 有 84.5% 的回應被評為有禮貌),但其中其實只有 41.7% 真正符合 Taarof 的文化規範。顯示現今泛用的、基於西方文化所建立的模型評估機制無法有效偵測到 Taarof 禮儀。所以就是現在的大型語言模型,嗯,還不太懂 Taarof。
解決方案:進行目標式訓練
不過,研究也提供了解決方案:將提示語言切換為波斯語,或是透過名為「目標式訓練與優化」 (Targeted Fine-tuning)、情境學習 (In-Context Learning, Few-shot),都能大幅提高 AI 對 Taarof 的準確率。
1.使用波斯語提示: 提示語言從英文切換到波斯語,是提升模型理解的最簡單的方法。
-成果:像是 DeepSeek V3 的準確率就從 36.6% 大幅提升至 68.6%(增加了 32.0 個百分點),表明語言本身是一種強大的文化背景線索!
2.目標式訓練與優化 (Targeted Fine-tuning):研究人員使用兩個特別的訓練方式,你可以想像成兩種不同的「家教」:一種是「監督式微調」(SFT),直接教導 AI 標準答案;另一種是「直接偏好優化」(DPO),則是透過比較「好」與「不好」的答案來讓 AI 學習價值觀。
-成果:透過 SFT,模型在測試集上的整體準確度提升了 20.0% [39, Table 2];DPO 的效果則非常突出,將 Llama 3 的準確度從訓練前的 37.2% 提升到 79.5% [39, Table 2],幾乎達到波斯母語人士的水平(81.8%)。
3.情境學習 (In-Context Learning, Few-shot):或被稱為「少樣本提示」(Few-shot Prompting),在不進行模型參數更新(訓練)的情況下,向模型提出 Taarof 情境問題時,同時附上少數幾個正確的範例,每個範例對應一個不同的社交互動主題(例如,如何回應稱讚、如何堅持付費等)。這些範例被插入到提示(Prompt)中,作為模型生成回應的上下文參考。
-成果:透過情境學習,Llama 3 模型在需要 Taarof 的情境中,準確率從原本的 37.2% 上升到 57.6%
總結
研究人員建議,他們採用的方法可以做為教育、旅遊、翻譯和國際交流……等「需要具有高度文化意識的 AI 工具」開發的參考。目前大型語言模型還是存在許多文化盲點,而這些盲點尚未經過研究人員測試。如果使用 LLMs 來進行不同文化和語言之間的翻譯,這些未經測試的盲點可能會產生重大的影響,希望未來的 AI 能不僅限於西方文化,而是有利於不同文化的人們之間進行更準確的溝通。
